
Trust, but Clone the Repo: Fact-Checking AI-Assisted Academic Papers
I audited three AI-assisted academic papers against their own code, data, and citations. The polish held up; the numbers did not.
I audited three AI-assisted academic papers against their own code, data, and citations. The polish held up; the numbers did not.

RUBICON makes a useful data-management argument for AI agents, but its 100% vs 0% benchmark result is too small and too stacked to carry the claim.
GitHub, Copilot billing, Ghostty, and security research show why teams should treat git forges as critical engineering infrastructure, not hosting.

SWE-bench Verified shows why AI coding benchmarks need stronger tests, contamination controls, and human review as coding agents rapidly improve.

GnuPG's ML-KEM support shows post-quantum cryptography moving from standards into everyday tools, and why crypto agility matters now for software teams.

A reflection on The Checklist Manifesto and why simple process tools can make complex professional work more reliable, repeatable, and resilient.
The xz/liblzma backdoor disclosure shows how release tarballs, build scripts, maintainership, and runtime linking become security surfaces now.
A refreshed look at Orca, explanation tuning, and why smaller language models need richer supervision, stronger data, and better evaluation.
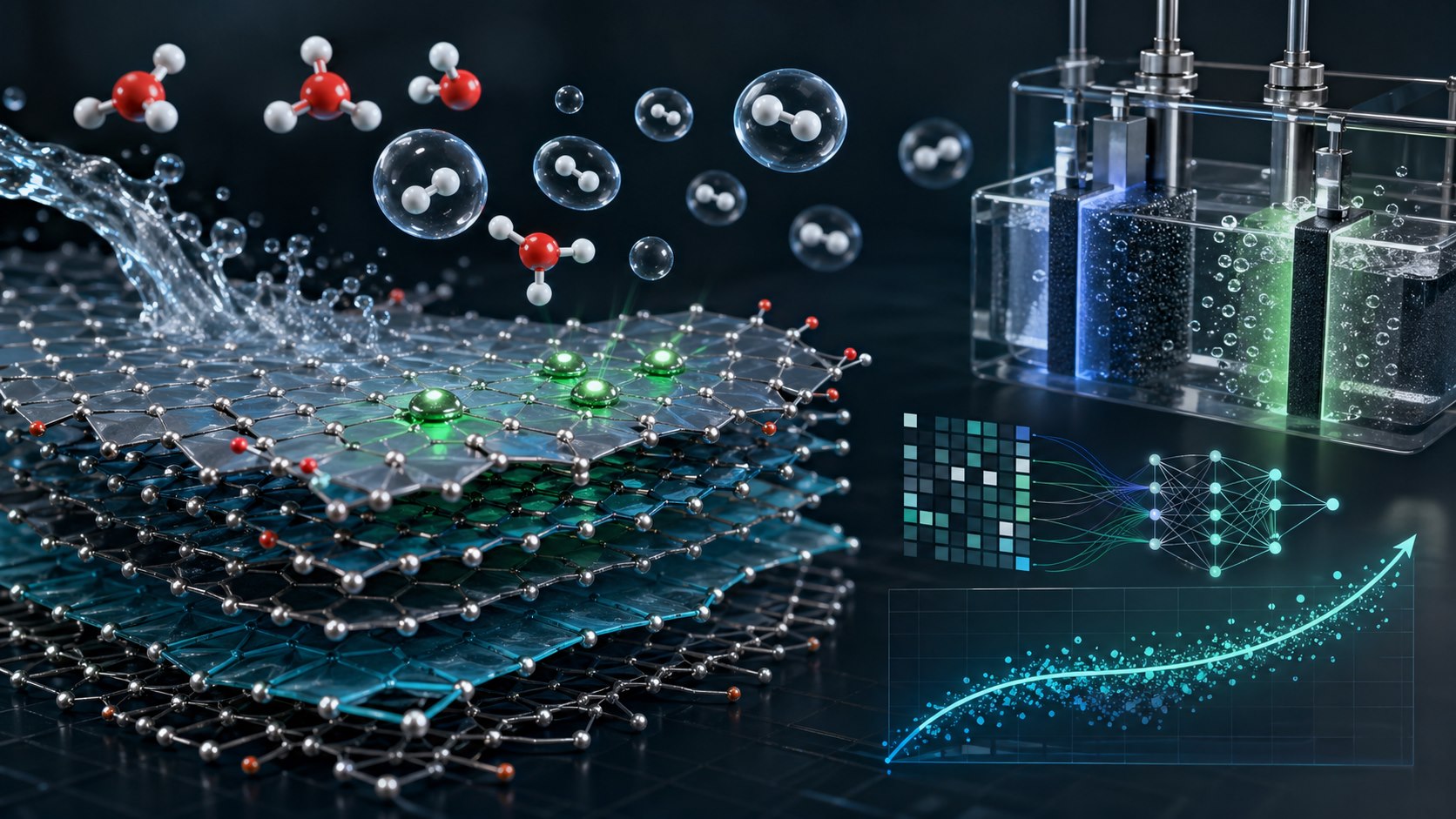
How machine learning can accelerate hydrogen evolution catalyst discovery by pairing materials descriptors, MXenes, and electrochemical insight.

A welcome post on rebuilding this site as a cleaner technical portfolio for software, AI, engineering, chemistry, physics, learning, and growth.